Delivering on the promise of real-time agentic automation requires a fast, reliable, and scalable data foundation. At UiPath, we needed a modern streaming architecture to underpin products like Maestro and Insights, enabling near real-time visibility into agentic automation metrics as they unfold. That journey led us to unify batch and streaming on Azure Databricks using Apache Spark™ Structured Streaming, enabling cost-efficient, low-latency analytics that support agentic decision-making across the enterprise.
This blog details the technical approach, trade-offs, and impact of these enhancements.
With Databricks-based streaming, we’ve achieved sub-minute event-to-warehouse latency while delivering simplified architecture and future-proof scalability, setting the new standard for event-driven data processing across UiPath.
Why Streaming Matters for UiPath Maestro and UiPath Insights
At UiPath, products like Maestro and Insights rely heavily on timely, reliable data. Maestro acts as the orchestration layer for our agentic automation platform; coordinating AI agents, robots, and humans based on real-time events. Whether it’s reacting to a system trigger, executing a long-running workflow, or including a human-in-the-loop step, Maestro depends on fast, accurate signal processing to make the right decisions.
UiPath Insights, which powers monitoring and analytics across these automations, adds another layer of demand: capturing key metrics and behavioral signals in near real time to surface trends, calculate ROI, and support issue detection.
Delivering these kinds of outcomes – reactive orchestration and real-time observability – requires a data pipeline architecture that’s not only low-latency, but also scalable, reliable, and maintainable. That need is what led us to rethink our streaming architecture on Azure Databricks.
Building the Streaming Data Foundation
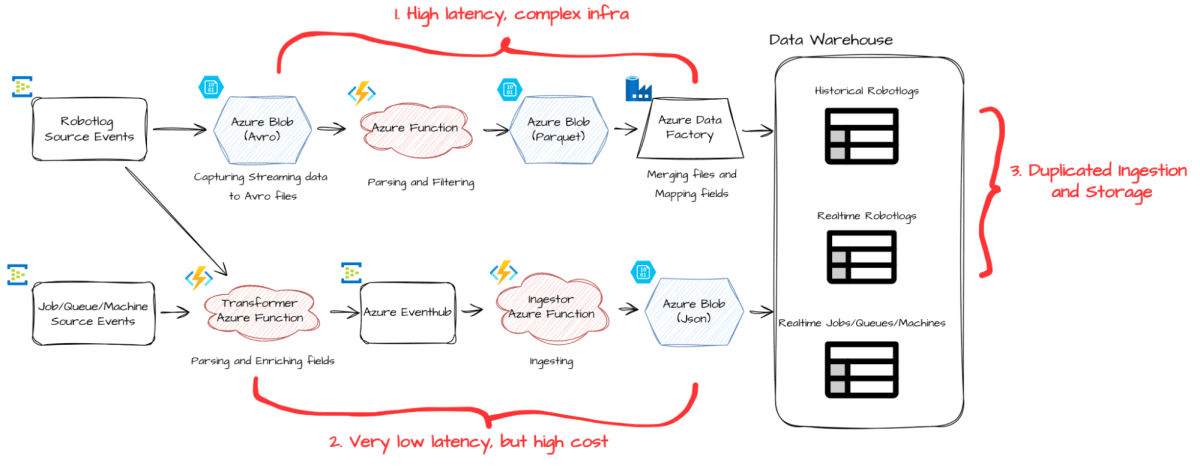
Delivering on the promise of powerful analytics and real-time monitoring requires a foundation of scalable, reliable data pipelines. Over the past few years, we have developed and expanded multiple pipelines to support new product features and respond to evolving business requirements. Now, we have the opportunity to assess how we can optimize these pipelines to not only save costs, but also have better scalability, and at-least once delivery guarantee to support data from new services like Maestro.
While our previous setup (shown above) worked well for our customers, it also revealed areas for improvement:
- The batching pipeline introduced up to 30 minutes of latency and relied on a complex infrastructure
- The real-time pipeline delivered faster data but came with higher cost.
- For Robotlogs, our largest dataset, we maintained separate ingestion and storage paths for both historical and real-time processing, resulting in duplication and inefficiency.
- To support the new ETL pipeline for UiPath Maestro, a new UiPath product, we would need to achieve at-least once delivery guarantee.
To address these challenges, we undertook a major architectural overhaul. We merged the batching and real-time ingestion processes for Robotlogs into a single pipeline, and re-architected the real-time ingestion pipeline to be more cost-efficient and scalable.
Why Spark Structured Streaming on Databricks?
As we set out to simplify and modernize our pipeline architecture, we needed a framework that could handle both high-throughput batch workloads and low-latency real-time data—without introducing operational overhead. Spark Structured Streaming (SSS) on Azure Databricks was a natural fit.
Built on top of Spark SQL and Spark Core, Structured Streaming treats real-time data as an unbounded table—allowing us to reuse familiar Spark batch constructs while gaining the benefits of a fault-tolerant, scalable streaming engine. This unified programming model reduced complexity and accelerated development.
We had already leveraged Spark Structured Streaming to develop our Real-time Alert feature, which utilizes stateful stream processing in Databricks. Now, we are expanding its capabilities to build our next generation of Real-time ingestion pipelines, enabling us to achieve low-latency, scalability, cost efficiency, and at-least-once delivery guarantees.
The Next Generation of Real-time Ingestion
Our new architecture, shown below, dramatically simplifies the data ingestion process by consolidating previously separate components into a unified, scalable pipeline using Spark Structured Streaming on Databricks:
At the core of this new design is a set of streaming jobs that read directly from event sources. These jobs perform parsing, filtering, flattening, and—most critically—join each event with reference data to enrich it before writing to our data warehouse.
We orchestrate these jobs using Databricks Lakeflow Jobs, which helps manage retries and job recovery in case of transient failures. This streamlined setup improves both developer productivity and system reliability.
The benefits of this new architecture include:
- Cost efficiency: Saves COGS by reducing infrastructure complexity and compute usage
- Low latency: Ingestion latency averages around one minute, with the flexibility to reduce this further
- Future-proof scalability: Throughput is proportional to the number of cores, and we can scale out infinitely
- No data lost: Spark does the heavy-lifting of failure recovery, supporting at-least once delivery.
- With downstream sink deduplication in future development, it will be able to achieve exactly once delivery
- Fast development cycle thanks to the Spark DataFrame API
- Simple and unified architecture
Low-Latency
Our streaming job currently runs in micro-batch mode with a one-minute trigger interval. This means that from the moment an event is published to our Event Bus, it typically lands in our data warehouse around 27 seconds on median, with 95% of records arriving within 51 seconds, and 99% within 72 seconds.
Structured Streaming provides configurable trigger settings, which could even bring down the latency to a few seconds. For now, we’ve chosen the one-minute trigger as the right balance between cost and performance, with the flexibility to lower it in the future if requirements change.
Scalability
Spark divides the big data work by partitions, which fully utilize the Worker/Executor CPU cores. Each Structured Streaming job is split into stages, which are further divided into tasks, each of which runs on a single core. This level of parallelization allows us to fully utilize our Spark cluster and scale efficiently with growing data volumes.
Thanks to optimizations like in-memory processing, Catalyst query planning, whole-stage code generation, and vectorized execution, we process around 40,000 events per second in scalability validation. If traffic increases, we can scale out simply by increasing partition counts on the source Event Bus and adding more worker nodes—ensuring future-proof scalability with minimal engineering effort.
Delivery Guarantee
Spark Structured Streaming provides exactly-once delivery by default, thanks to its checkpointing system. After each micro-batch, Spark persists the progress (or “epoch”) of each source partition as write-ahead logs and the job’s application state in state store. In the event of a failure, the job resumes from the last checkpoint—ensuring no data is lost or skipped.
This is mentioned in the original Spark Structured Streaming research paper, which states that achieving exactly-once delivery requires:
- The input source to be replayable
- The output sink to support idempotent writes
But there’s also an implicit third requirement that often goes unspoken: the system must be able to detect and handle failures gracefully.
This is where Spark works well—its robust failure recovery mechanisms can detect task failures, executor crashes, and driver issues, and automatically take corrective actions such as retries or restarts.
Note that we are currently operating with at-least once delivery, as our output sink is not idempotent yet. If we have further requirements of exactly-once delivery in the future, as long as we put further engineering efforts into idempotency, we should be able to achieve it.
Raw Data is Better
We have also made some other improvements. We have now included and persisted a common rawMessage field across all tables. This column stores the original event payload as a raw string. To borrow the sushi principle (although we mean a slightly different thing here): raw data is better.
Raw data significantly simplifies troubleshooting. When something goes wrong—like a missing field or unexpected value—we can instantly refer to the original message and trace the issue, without chasing down logs or upstream systems. Without this raw payload, diagnosing data issues becomes much harder and slower.
The downside is a small increase in storage. But thanks to cheap cloud storage and the columnar format of our warehouse, this has minimal cost and no impact on query performance.
Simple and Powerful API
The new implementation is taking us less development time. This is largely thanks to the DataFrame API in Spark, which provides a high-level, declarative abstraction over distributed data processing. In the past, using RDDs meant manually reasoning about execution plans, understanding DAGs, and optimizing the order of operations like joins and filters. DataFrames allow us to focus on the logic of what we want to compute, rather than how to compute it. This significantly simplifies the development process.
This has also improved operations. We no longer need to manually rerun failed jobs or trace errors across multiple pipeline components. With a simplified architecture and fewer moving parts, both development and debugging are significantly easier.
Driving Real-Time Analytics Across UiPath
The success of this new architecture has not gone unnoticed. It has quickly become the new standard for real-time event ingestion across UiPath. Beyond its initial implementation for UiPath Maestro and Insights, the pattern has been widely adopted by multiple new teams and projects for their real-time analytics needs, including those working on cutting-edge initiatives. This widespread adoption is a testament to the architecture’s scalability, efficiency, and extensibility, making it easy for new teams to onboard and enabling a new generation of products with powerful real-time analytics capabilities.
If you’re looking to scale your real-time analytics workloads without the operational burden, the architecture outlined here offers a proven path, powered by Databricks and Spark Structured Streaming and ready to support the next generation of AI and agentic systems.
About UiPath
UiPath (NYSE: PATH) is a global leader in agentic automation, empowering enterprises to harness the full potential of AI agents to autonomously execute and optimize complex business processes. The UiPath Platform™ uniquely combines controlled agency, developer flexibility, and seamless integration to help organizations scale agentic automation safely and confidently. Committed to security, governance, and interoperability, UiPath supports enterprises as they transition into a future where automation delivers on the full potential of AI to transform industries.


{kind=link}