Evaluating large language models (LLMs) is both scientifically and economically costly. As the field races toward ever-larger models, the methodology for evaluating and comparing them becomes increasingly critical—not just for benchmark scores, but for informed development decisions. Recent research from the Allen Institute for Artificial Intelligence (Ai2) introduces a robust framework centered around two fundamental metrics: signal and noise, and their ratio, known as the signal-to-noise ratio (SNR). This framework provides actionable insights to reduce uncertainty and improve reliability in language model evaluation, with tangible interventions validated across hundreds of models and diverse benchmarks.
Understanding Signal and Noise in LLM Evaluation
Signal
Signal measures the ability of a benchmark to distinguish better models from worse ones, essentially quantifying the spread in model scores for a given task. A high signal means that model performances are distributed widely across the benchmark, making it easier to rank and compare models meaningfully. A benchmark with low signal will have scores that are too close together, making it more difficult to identify which model is truly better.
Noise
Noise refers to the variability of a benchmark score as a result of random fluctuations during training—including random initialization, data order, and checkpoint-to-checkpoint changes within a single training run. High noise makes a benchmark less reliable, as repeated experiments can yield inconsistent results even with the same model and data configuration.
Signal-to-Noise Ratio (SNR)
Ai2’s key insight is that the utility of a benchmark for model development is governed not just by the signal or the noise individually, but by their ratio—the signal-to-noise ratio. Benchmarks with high SNR consistently yield more reliable evaluations and are better suited for making small-scale decisions that transfer to large model scales.
Why SNR Matters for Development Decisions
There are two common scenarios in LLM development where evaluation benchmarks guide critical decisions:
- Decision Accuracy: Training several small models (e.g., on different data recipes) and selecting the best for scaling up. The core question: does the ranking of models at small scale hold for larger scale?
- Scaling Law Prediction Error: Fitting a scaling law based on small models to predict the performance of a much larger model.
Research demonstrates that high-SNR benchmarks are far more reliable for these scenarios. The SNR correlates strongly with decision accuracy (R2=0.626R^2 = 0.626R2=0.626) and also predicts the likelihood of scaling law prediction error (R2=0.426R^2 = 0.426R2=0.426). Benchmarks with low signal or high noise make development choices riskier as small-scale findings may not hold at production scale.
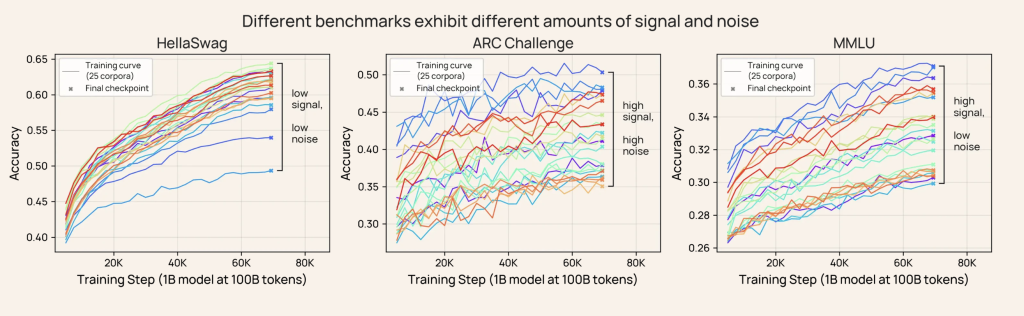
Measuring Signal and Noise
Practical Definition
- Signal: Measured as the maximum difference (dispersion) in scores between any two models, normalized by the mean score, for a population of models trained under similar compute budgets.
- Noise: Estimated as the relative standard deviation of scores among the final nnn checkpoints of a single model’s training.
The combination, SNR= Relative Standard Deviation (Noise)/ Relative Dispersion (Signal)
offers a cheap and reliable way to characterize evaluation robustness. Importantly, checkpoint-to-checkpoint noise is highly correlated with traditional sources such as initialization and data order noise, making it a practical proxy for overall modeling noise.
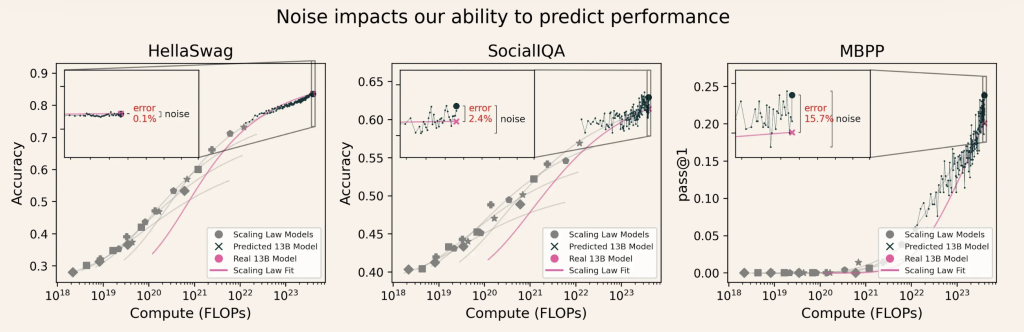
Interventions: How to Improve Evaluation Benchmarks
Ai2 proposes and tests several practical interventions to boost benchmark SNR—empowering better decisions during LLM development.
1. Filtering Subtasks by SNR
Multi-task benchmarks (e.g., MMLU, AutoBencher) are often averages over many subtasks. The research shows that selecting a subset of high-SNR subtasks (rather than using all available tasks or larger sample sizes) dramatically improves both SNR and decision accuracy. For instance, using only the top 16 out of 57 MMLU subtasks results in higher SNR and better predictions than using the full set. This approach also helps weed out subtasks with high labeling errors, as low-SNR subtasks often correspond to poor data quality.
2. Averaging Checkpoint Scores
Rather than relying solely on the final training checkpoint, averaging the scores over several final checkpoints (or using exponential moving averages during training) reduces the impact of transient noise. This method consistently raises decision accuracy and lowers scaling law prediction errors. For example, averaging improved decision accuracy by 2.4% and reduced prediction errors for the majority of benchmarks examined.
3. Using Continuous Metrics Like Bits-Per-Byte (BPB)
Classification metrics like accuracy do not fully exploit the continuous nature of LLM outputs. Measuring bits-per-byte (a continuous metric related to perplexity) yields substantially higher SNR, particularly in generative tasks such as math and code. The shift from accuracy to BPB boosts the SNR for GSM8K from 1.2 to 7.0, and for MBPP from 2.0 to 41.8, resulting in marked improvements in decision accuracy (e.g., MBPP goes from 68% to 93%, Minerva MATH from 51% to 90%).
Key Takeaways
- SNR as a Benchmark Selection Tool: When choosing benchmarks for LLM evaluation, aim for high signal-to-noise ratio. This ensures that decisions made with small-scale experiments are predictive at production scale.
- Quality over Quantity: Larger benchmarks or more data is not always better. SNR-informed subtask selection and metric choice materially improve evaluation quality.
- Early Stopping and Smoothing: During development, average results across final or intermediate checkpoints to mitigate random noise and boost reliability.
- Continuous Metrics Improve Reliability: Prefer continuous metrics (BPB, perplexity) over classification metrics for challenging and generative tasks; this greatly increases SNR and result stability.
Conclusion
Ai2’s signal and noise framework reshapes how model developers should approach LLM benchmarking and evaluation. By focusing on statistical properties through the lens of SNR, practitioners can reduce decision risk, anticipate scaling law behavior, and select optimal benchmarks for model development and deployment. The research is augmented by Ai2’s public dataset of 900,000 evaluations on 465 open-weight models, offering the community robust tools for further advances in LLM evaluation science.
Check out the Paper, Technical Blog, GitHub Page and Hugging Face Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.

