Retrieval-Augmented Generation (RAG) has emerged as a cornerstone technique for enhancing Large Language Models (LLMs) with real-time, domain-specific knowledge. But the landscape is rapidly shifting—today, the most common implementations are “Native RAG” pipelines, and a new paradigm called “Agentic RAG” is redefining what’s possible in AI-powered information synthesis and decision support.
Native RAG: The Standard Pipeline
Architecture
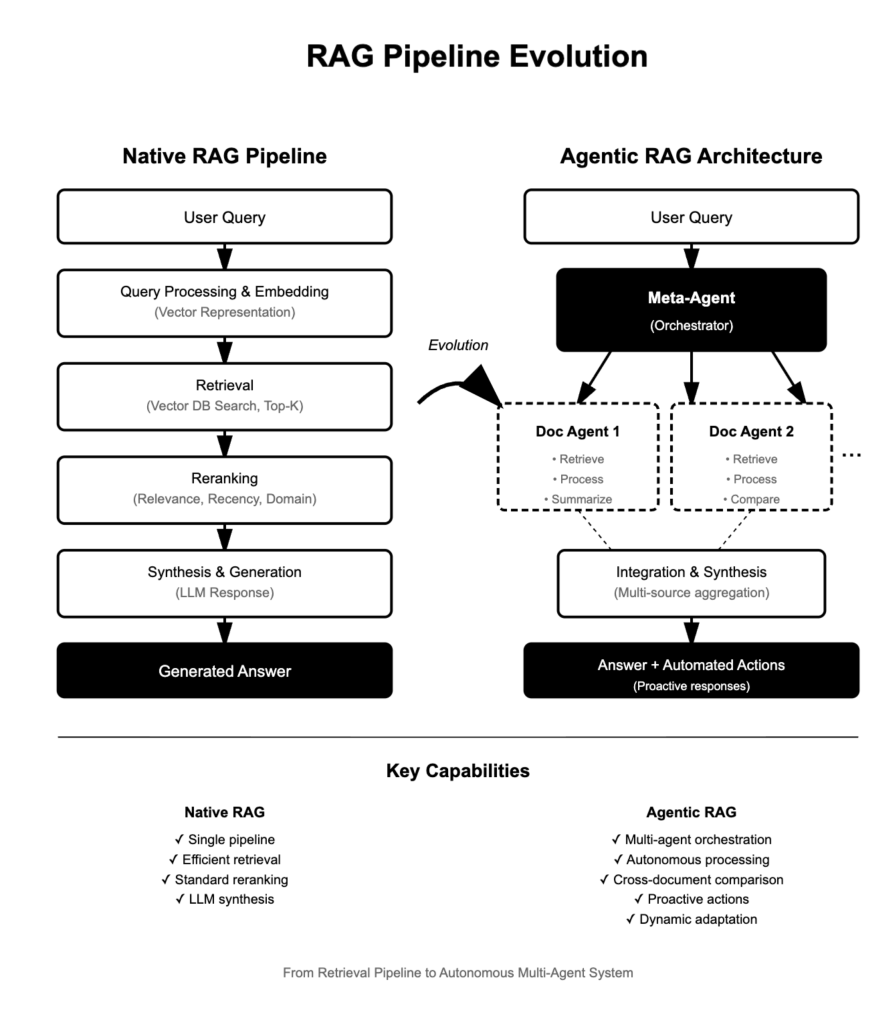
A Native RAG pipeline harnesses retrieval and generation-based methods to answer complex queries while ensuring accuracy and relevance. The pipeline typically involves:
- Query Processing & Embedding: The user’s question is rewritten, if needed, embedded into a vector representation using an LLM or dedicated embedding model, and prepared for semantic search.
- Retrieval: The system searches a vector database or document store, identifying top-k relevant chunks using similarity metrics (cosine, Euclidean, dot product). Efficient ANN algorithms optimize this stage for speed and scalability.
- Reranking: Retrieved results are reranked based on relevance, recency, domain-specificity, or user preference. Reranking models—ranging from rule-based to fine-tuned ML systems—prioritize the highest-quality information.
- Synthesis & Generation: The LLM synthesizes the reranked information to generate a coherent, context-aware response for the user.
Common Optimizations
Recent advances include dynamic reranking (adjusting depth by query complexity), fusion-based strategies that aggregate rankings from multiple queries, and hybrid approaches that combine semantic partitioning with agent-based selection for optimal retrieval robustness and latency.
Agentic RAG: Autonomous, Multi-Agent Information Workflows
What Is Agentic RAG?
Agentic RAG is an agent-based approach to RAG, leveraging multiple autonomous agents to answer questions and process documents in a highly coordinated fashion. Rather than a single retrieval/generation pipeline, Agentic RAG structures its workflow for deep reasoning, multi-document comparison, planning, and real-time adaptability.
Key Components
| Component | Description |
|---|---|
| Document Agent | Each document is assigned its own agent, able to answer queries about the document and perform summary tasks, working independently within its scope. |
| Meta-Agent | Orchestrates all document agents, managing their interactions, integrating outputs, and synthesizing a comprehensive answer or action. |
Features and Benefits
- Autonomy: Agents operate independently, retrieving, processing, and generating answers or actions for specific documents or tasks.
- Adaptability: The system dynamically adjusts its strategy (e.g., reranking depth, document prioritization, tool selection) based on new queries or changing data contexts.
- Proactivity: Agents anticipate needs, take preemptive steps towards goals (e.g., pulling additional sources or suggesting actions), and learn from previous interactions.
Advanced Capabilities
Agentic RAG goes beyond “passive” retrieval—agents can compare documents, summarize or contrast specific sections, aggregate multi-source insights, and even invoke tools or APIs for enriched reasoning. This enables:
- Automated research and multi-database aggregation
- Complex decision support (e.g., comparing technical features, summarizing key differences across product sheets)
- Executive support tasks that require independent synthesis and real-time action recommendation.
Applications
Agentic RAG is ideal for scenarios where nuanced information processing and decision-making are required:
- Enterprise Knowledge Management: Coordinating answers across heterogeneous internal repositories
- AI-Driven Research Assistants: Cross-document synthesis for technical writers, analysts, or executives
- Automated Action Workflows: Triggering actions (e.g., responding to invitations, updating records) after multi-step reasoning over documents or databases.
- Complex Compliance and Security Audits: Aggregating and comparing evidence from varied sources in real time.
Conclusion
Native RAG pipelines have standardized the process of embedding, retrieving, reranking, and synthesizing answers from external data, enabling LLMs to serve as dynamic knowledge engines. Agentic RAG pushes the boundaries even further—by introducing autonomous agents, orchestration layers, and proactive, adaptive workflows, it transforms RAG from a retrieval tool into a full-blown agentic framework for advanced reasoning and multi-document intelligence.
Organizations seeking to move beyond basic augmentation—and into realms of deep, flexible AI orchestration—will find in Agentic RAG the blueprint for the next generation of intelligent systems.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.