Introduction
Understanding how the brain builds internal representations of the visual world is one of the most fascinating challenges in neuroscience. Over the past decade, deep learning has reshaped computer vision, producing neural networks that not only perform at human-level accuracy on recognition tasks but also seem to process information in ways that resemble our brains. This unexpected overlap raises an intriguing question: can studying AI models help us better understand how the brain itself learns to see?
Researchers at Meta AI and École Normale Supérieure set out to explore this question by focusing on DINOv3, a self-supervised vision transformer trained on billions of natural images. They compared DINOv3’s internal activations with human brain responses to the same images, using two complementary neuroimaging techniques. fMRI provided high-resolution spatial maps of cortical activity, while MEG captured the precise timing of brain responses. Together, these datasets offered a rich view of how the brain processes visual information.
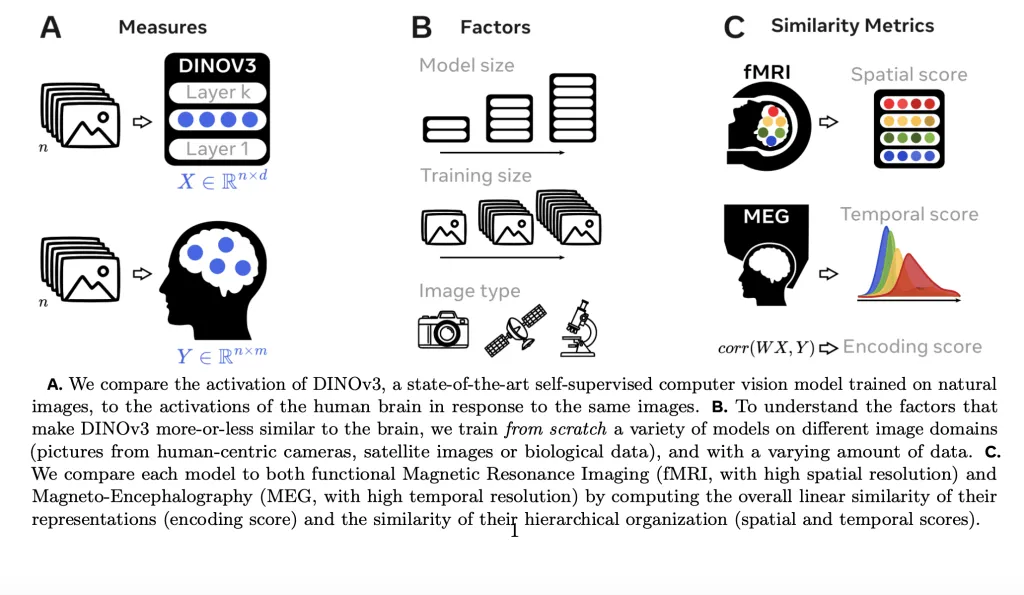
Technical Details
The research team explores three factors that might drive brain-model similarity: model size, the amount of training data, and the type of images used for training. To do this, the team trained multiple versions of DINOv3, varying these factors independently.
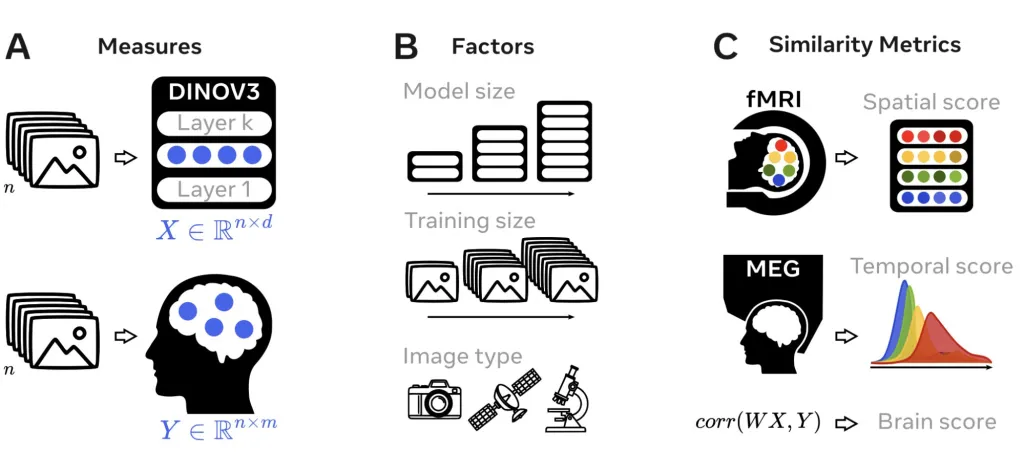
Brain-Model Similarity
The research team found strong evidence of convergence while looking at how well DINOv3 matched brain responses. The model’s activations predicted fMRI signals in both early visual regions and higher-order cortical areas. Peak voxel correlations reached R = 0.45, and MEG results showed that alignment started as early as 70 milliseconds after image onset and lasted up to three seconds. Importantly, early DINOv3 layers aligned with regions like V1 and V2, while deeper layers matched activity in higher-order regions, including parts of the prefrontal cortex.
Training Trajectories
Tracking these similarities over the course of training revealed a developmental trajectory. Low-level visual alignments emerged very early, after only a small fraction of training, while higher-level alignments required billions of images. This mirrors the way the human brain develops, with sensory areas maturing earlier than associative cortices. The study showed that temporal alignment emerged fastest, spatial alignment more slowly, and encoding similarity in between, highlighting the layered nature of representational development.
Role of Model Factors
The role of model factors was equally telling. Larger models consistently achieved higher similarity scores, especially in higher-order cortical regions. Longer training improved alignment across the board, with high-level representations benefiting most from extended exposure. The type of images mattered as well: models trained on human-centric images produced the strongest alignment. Those trained on satellite or cellular images showed partial convergence in early visual regions but much weaker similarity in higher-level brain areas. This suggests that ecologically relevant data are crucial for capturing the full range of human-like representations.
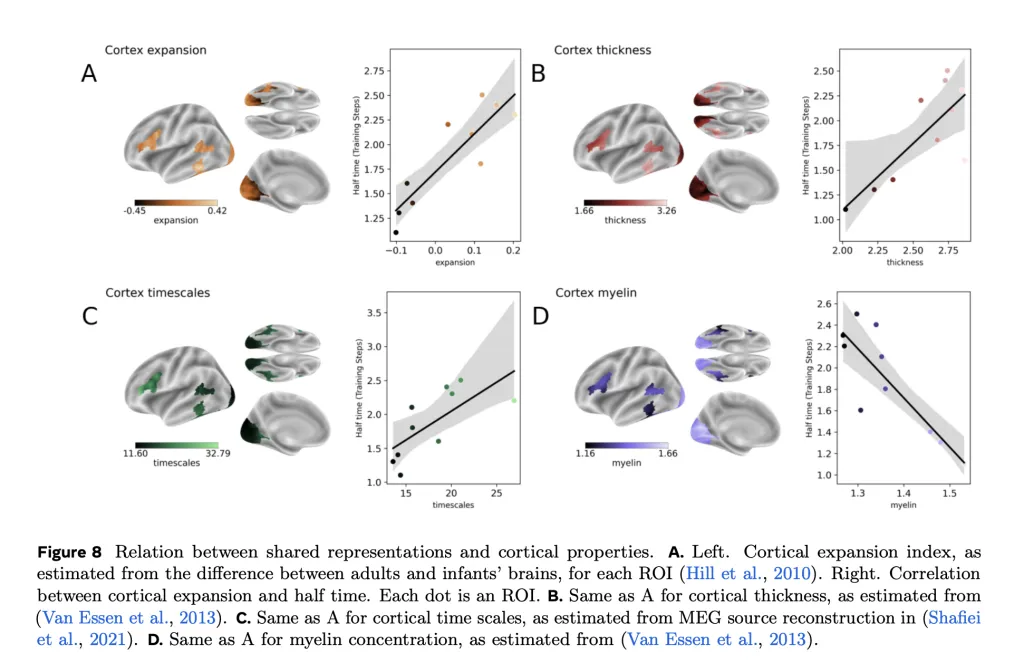
Links to Cortical Properties
Interestingly, the timing of when DINOv3’s representations emerged also lined up with structural and functional properties of the cortex. Regions with greater developmental expansion, thicker cortex, or slower intrinsic timescales aligned later in training. Conversely, highly myelinated regions aligned earlier, reflecting their role in fast information processing. These correlations suggest that AI models can offer clues about the biological principles underlying cortical organization.
Nativism vs. Empiricism
The study highlights a balance between innate structure and learning. DINOv3’s architecture gives it a hierarchical processing pipeline, but full brain-like similarity only emerged with prolonged training on ecologically valid data. This interplay between architectural priors and experience echoes debates in cognitive science about nativism and empiricism.
Developmental Parallels
The parallels to human development are striking. Just as sensory cortices in the brain mature quickly and associative areas develop more slowly, DINOv3 aligned with sensory regions early in training and with prefrontal areas much later. This suggests that training trajectories in large-scale AI models may serve as computational analogues for the staged maturation of human brain functions.
Beyond the Visual Pathway
The results also extended beyond traditional visual pathways. DINOv3 showed alignment in prefrontal and multimodal regions, raising questions about whether such models capture higher-order features relevant for reasoning and decision-making. While this study focused only on DINOv3, it points toward exciting possibilities for using AI as a tool to test hypotheses about brain organization and development.
Conclusion
In conclusion, this research shows that self-supervised vision models like DINOv3 are more than just powerful computer vision systems. They also approximate aspects of human visual processing, revealing how size, training, and data shape convergence between brains and machines. By studying how models learn to “see,” we gain valuable insights into how the human brain itself develops the ability to perceive and interpret the world.
Check out the PAPER here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.

