Alibaba’s Qwen Team unveiled Qwen3-Max-Preview (Instruct), a new flagship large language model with over one trillion parameters—their largest to date. It is accessible through Qwen Chat, Alibaba Cloud API, OpenRouter, and as default in Hugging Face’s AnyCoder tool.
How does it fit in today’s LLM landscape?
This milestone comes at a time when the industry is trending toward smaller, more efficient models. Alibaba’s decision to move upward in scale marks a deliberate strategic choice, highlighting both its technical capabilities and commitment to trillion-parameter research.
How large is Qwen3-Max and what are its context limits?
- Parameters: >1 trillion.
- Context window: Up to 262,144 tokens (258,048 input, 32,768 output).
- Efficiency feature: Includes context caching to speed up multi-turn sessions.
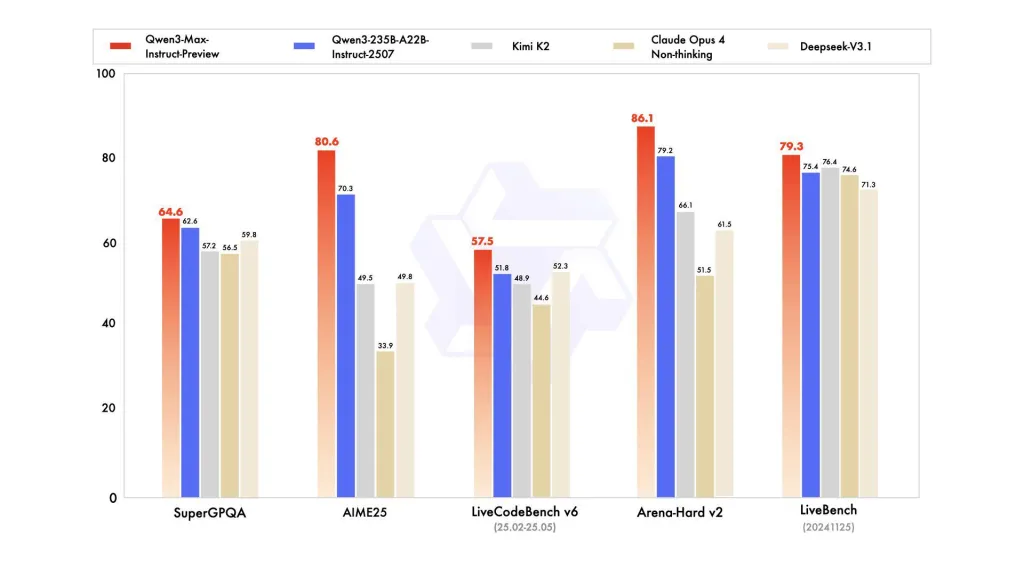
How does Qwen3-Max perform against other models?
Benchmarks show it outperforms Qwen3-235B-A22B-2507 and competes strongly with Claude Opus 4, Kimi K2, and Deepseek-V3.1 across SuperGPQA, AIME25, LiveCodeBench v6, Arena-Hard v2, and LiveBench.
What is the pricing structure for usage?
Alibaba Cloud applies tiered token-based pricing:
- 0–32K tokens: $0.861/million input, $3.441/million output
- 32K–128K: $1.434/million input, $5.735/million output
- 128K–252K: $2.151/million input, $8.602/million output
This model is cost-efficient for smaller tasks but scales up significantly in price for long-context workloads.
How does the closed-source approach impact adoption?
Unlike earlier Qwen releases, this model is not open-weight. Access is restricted to APIs and partner platforms. This choice highlights Alibaba’s commercialization focus but may slow broader adoption in research and open-source communities
Key Takeaways
- First trillion-parameter Qwen model – Qwen3-Max surpasses 1T parameters, making it Alibaba’s largest and most advanced LLM to date.
- Ultra-long context handling – Supports 262K tokens with caching, enabling extended document and session processing beyond most commercial models.
- Competitive benchmark performance – Outperforms Qwen3-235B and competes with Claude Opus 4, Kimi K2, and Deepseek-V3.1 on reasoning, coding, and general tasks.
- Emergent reasoning despite design – Though not marketed as a reasoning model, early results show structured reasoning capabilities on complex tasks.
- Closed-source, tiered pricing model – Available via APIs with token-based pricing; economical for small tasks but costly at higher context usage, limiting accessibility.
Summary
Qwen3-Max-Preview sets a new scale benchmark in commercial LLMs. Its trillion-parameter design, 262K context length, and strong benchmark results highlight Alibaba’s technical depth. Yet the model’s closed-source release and steep tiered pricing create a question for broader accessibility.
Check out the Qwen Chat and Alibaba Cloud API. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.

