What Is ProRLv2?
ProRLv2 is the latest version of NVIDIA’s Prolonged Reinforcement Learning (ProRL), designed specifically to push the boundaries of reasoning in large language models (LLMs). By scaling reinforcement learning (RL) steps from 2,000 up to 3,000, ProRLv2 systematically tests how extended RL can unlock new solution spaces, creativity, and high-level reasoning that were previously inaccessible—even with smaller models like the 1.5B-parameter Nemotron-Research-Reasoning-Qwen-1.5B-v2.
Key Innovations in ProRLv2
ProRLv2 incorporates several innovations to overcome common RL limitations in LLM training:
- REINFORCE++- Baseline: A robust RL algorithm that enables long-horizon optimization over thousands of steps, handling the instability typical in RL for LLMs.
- KL Divergence Regularization & Reference Policy Reset: Periodically refreshes the reference model with the current best checkpoint, allowing stable progress and continued exploration by preventing the RL objective from dominating too early.
- Decoupled Clipping & Dynamic Sampling (DAPO): Encourages diverse solution discovery by boosting unlikely tokens and focusing learning signals on prompts of intermediate difficulty.
- Scheduled Length Penalty: Cyclically applied, helping maintain diversity and prevent entropy collapse as training lengthens.
- Scaling Training Steps: ProRLv2 moves the RL training horizon from 2,000 to 3,000 steps, directly testing how much longer RL can expand reasoning abilities.
How ProRLv2 Expands LLM Reasoning
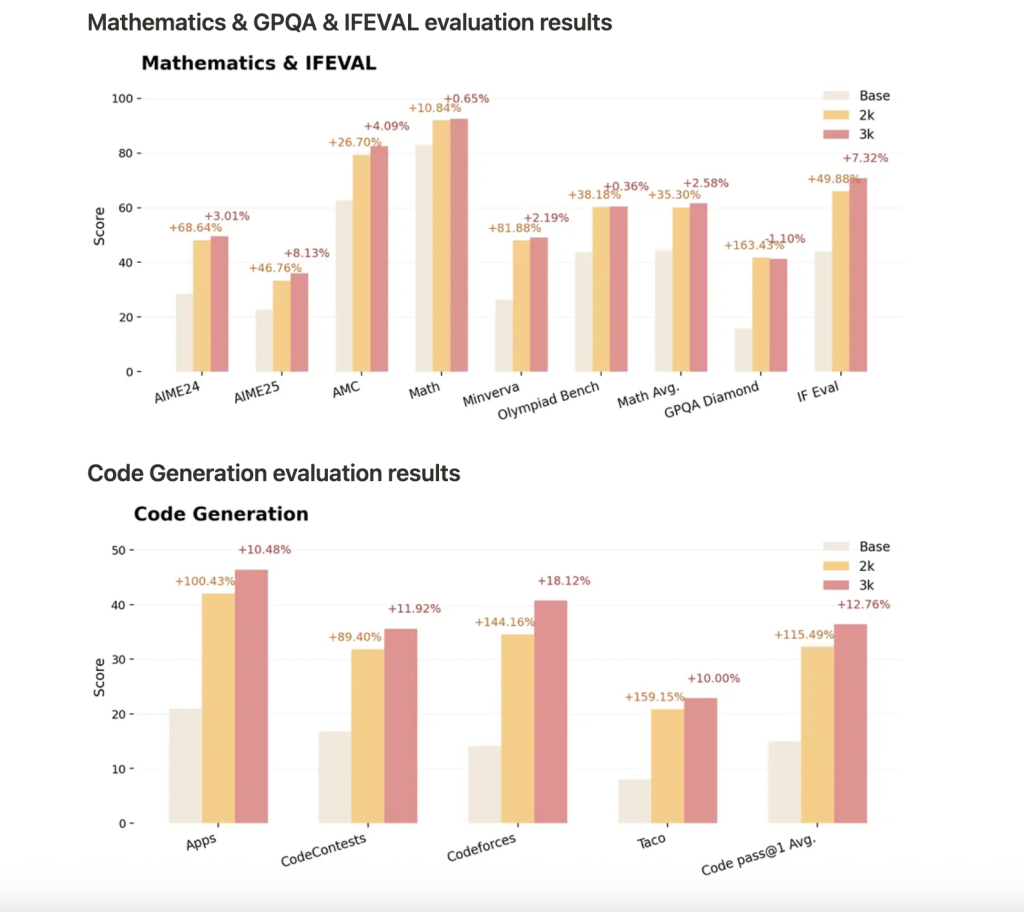
Nemotron-Research-Reasoning-Qwen-1.5B-v2, trained with ProRLv2 for 3,000 RL steps, sets a new standard for open-weight 1.5B models on reasoning tasks, including math, code, science, and logic puzzles:
- Performance surpasses previous versions and competitors like DeepSeek-R1-1.5B.
- Sustained gains with more RL steps: Longer training leads to continual improvements, especially on tasks where base models perform poorly, demonstrating genuine expansion in reasoning boundaries.
- Generalization: Not only does ProRLv2 boost pass@1 accuracy, but it also enables novel reasoning and solution strategies on tasks not seen during training.
- Benchmarks: Gains include average pass@1 improvements of 14.7% in math, 13.9% in coding, 54.8% in logic puzzles, 25.1% in STEM reasoning, and 18.1% in instruction-following tasks, with further improvements in v2 on unseen and harder benchmarks.
Why It Matters
The major finding of ProRLv2 is that continued RL training, with careful exploration and regularization, reliably expands what LLMs can learn and generalize. Rather than hitting an early plateau or overfitting, prolonged RL allows smaller models to rival much larger ones in reasoning—demonstrating that scaling RL itself is as important as model or dataset size.
Using Nemotron-Research-Reasoning-Qwen-1.5B-v2
The latest checkpoint is available for testing on Hugging Face. Loading the model:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("nvidia/Nemotron-Research-Reasoning-Qwen-1.5B")
model = AutoModelForCausalLM.from_pretrained("nvidia/Nemotron-Research-Reasoning-Qwen-1.5B")
Conclusion
ProRLv2 redefines the limits of reasoning in language models by showing that RL scaling laws matter as much as size or data. Through advanced regularization and smart training schedules, it enables deep, creative, and generalizable reasoning even in compact architectures. The future lies in how far RL can push—not just how big models can get.
Check out the Unofficial Blog and Model on Hugging Face here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.

{kind=link}