How can we make every node in a graph its own intelligent agent—capable of personalized reasoning, adaptive retrieval, and autonomous decision-making? This is the core question explored by a group researchers from Rutgers University. The research team introduced ReaGAN—a Retrieval-augmented Graph Agentic Network that reimagines each node as an independent reasoning agent.
Why Traditional GNNs Struggle
Graph Neural Networks (GNNs) are the backbone for many tasks like citation network analysis, recommendation systems, and scientific categorization. Traditionally, GNNs operate via static, homogeneous message passing: each node aggregates information from its immediate neighbors using the same predefined rules.
But two persistent challenges have emerged:
- Node Informativeness Imbalance: Not all nodes are created equal. Some nodes carry rich, useful information while others are sparse and noisy. When treated identically, valuable signals can get lost, or irrelevant noise can overpower useful context.
- Locality Limitations: GNNs focus on local structure—information from nearby nodes—often missing out on meaningful, semantically similar but distant nodes within the larger graph.
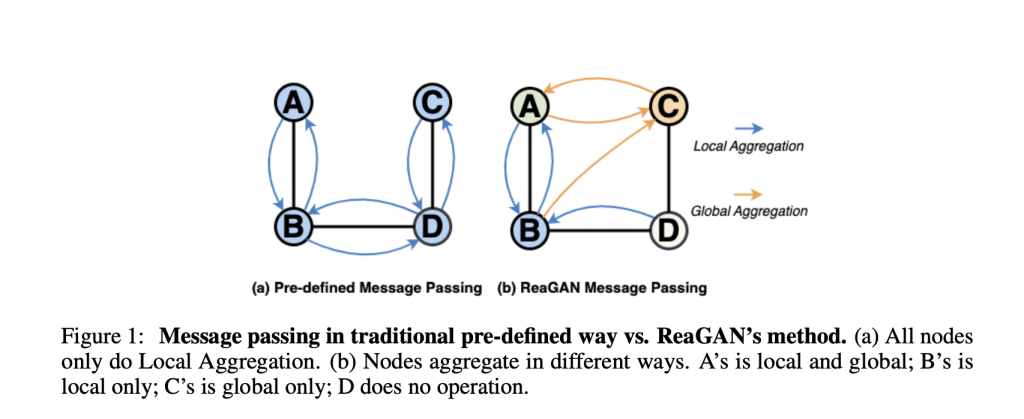
The ReaGAN Approach: Nodes as Autonomous Agents
ReaGAN flips the script. Instead of passive nodes, each node becomes an agent that actively plans its next move based on its memory and context. Here’s how:
- Agentic Planning: Nodes interact with a frozen large language model (LLM), such as Qwen2-14B, to dynamically decide actions (“Should I gather more info? Predict my label? Pause?”).
- Flexible Actions:
- Local Aggregation: Harvest information from direct neighbors.
- Global Aggregation: Retrieve relevant insights from anywhere on the graph—using retrieval-augmented generation (RAG).
- NoOp (“Do Nothing”): Sometimes, the best move is to wait—pausing to avoid information overload or noise.
- Memory Matters: Each agent node maintains a private buffer for its raw text features, aggregated context, and a set of labeled examples. This allows tailored prompting and reasoning at every step.
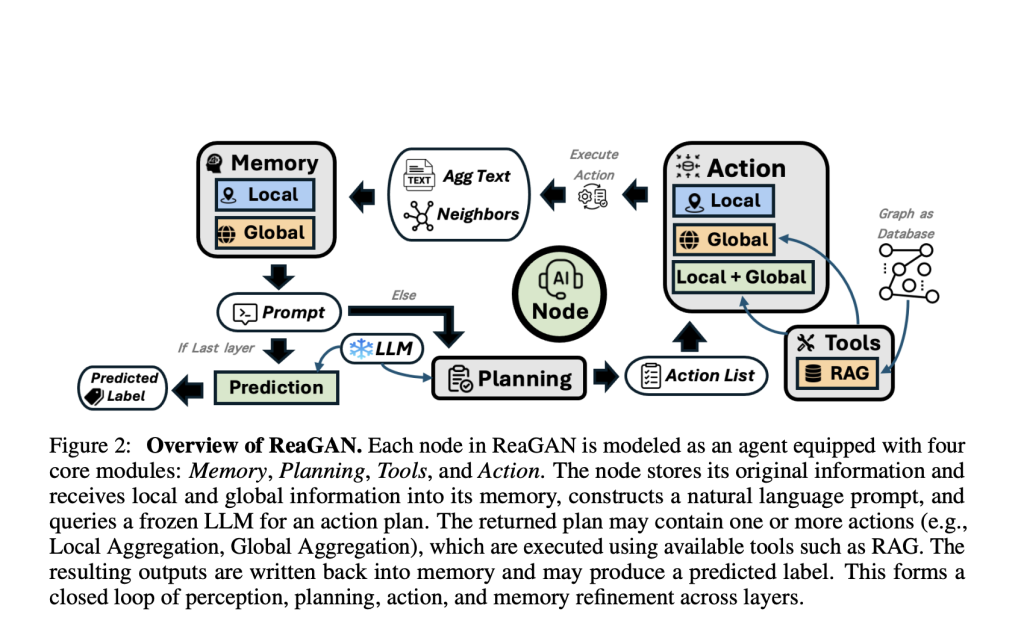
How Does ReaGAN Work?
Here’s a simplified breakdown of the ReaGAN workflow:
- Perception: The node gathers immediate context from its own state and memory buffer.
- Planning: A prompt is constructed (summarizing the node’s memory, features, and neighbor info) and sent to an LLM, which recommends the next action(s).
- Acting: The node may aggregate locally, retrieve globally, predict its label, or take no action. Outcomes are written back to memory.
- Iterate: This reasoning loop runs for several layers, allowing information integration and refinement.
- Predict: In the final stage, the node aims to make a label prediction—supported by the blended local and global evidence it’s gathered.
What makes this novel is that every node decides for itself, asynchronously. There’s no global clock or shared parameters forcing uniformity.
Results: Surprisingly Strong—Even Without Training
ReaGAN’s promise is matched by its results. On classic benchmarks (Cora, Citeseer, Chameleon), it achieves competitive accuracy, often matching or outperforming baseline GNNs—without any supervised training or fine-tuning.
Sample Results:
| Model | Cora | Citeseer | Chameleon |
|---|---|---|---|
| GCN | 84.71 | 72.56 | 28.18 |
| GraphSAGE | 84.35 | 78.24 | 62.15 |
| ReaGAN | 84.95 | 60.25 | 43.80 |
ReaGAN uses a frozen LLM for planning and context gathering—highlighting the power of prompt engineering and semantic retrieval.
Key Insights
- Prompt Engineering Matters: How nodes combine local and global memory in prompts impacts accuracy, and the best strategy depends on graph sparsity and label locality.
- Label Semantics: Exposing explicit label names can lead to biased predictions; anonymizing labels yields better results.
- Agentic Flexibility: ReaGAN’s decentralized, node-level reasoning is particularly effective in sparse graphs or those with noisy neighborhoods.
Summary
ReaGAN sets a new standard for agent-based graph learning. With the increasing sophistication of LLMs and retrieval-augmented architectures, we might soon see graphs where every node is not just a number or an embedding, but an adaptive, contextually-aware reasoning agent—ready to tackle the challenges of tomorrow’s data networks.
Check out the Paper here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.