Hey guys
Picture this: your team has just released a slick new LLM-powered application—maybe it’s a summarizing tool built into your dashboard, or a smart chatbot for customer support.
It dazzled in demos. Leadership was thrilled. But a week later, a user triggers a weird edge case. You patch it. Then another team wants to reuse the model for a new use case. You tweak the logic, rewire some APIs, and… boom. The chatbot breaks. Again.
Welcome to the monolith trap in the age of generative AI
As large language models (LLMs) become embedded in more products, engineering teams are discovering a harsh truth: the magic of LLMs doesn’t scale well in a tightly coupled architecture. A modification in one component might have unpredictable effects on other components, transforming features that first appeared to be easy wins into fragile systems. Debugging turns become an absolute nightmare. Experimentation slows. Confidence erodes.
But there’s a better way.


From Monoliths to Modules: The Rise of Plugin Architectures
Plugin architectures have the potential to revolutionize LLM-based products in the same way that microservices revolutionized the creation of web applications. Teams are using a modular approach, where each AI capacity (such as summarization, translation, question-answering, and classification) is encapsulated as a distinct, pluggable unit, rather than creating a single, interdependent codebase where all of the features are intertwined.
It is possible for these “plugins” to be independently created, tested, implemented, tracked, and improved.
They communicate with an API layer or central orchestrator that routes requests according to system status, user intent, or context. Additionally, plugins may be changed or adjusted without worrying about the entire system malfunctioning because they are loosely connected.
Consider using Lego bricks for construction rather than a single piece of wood for carving. That’s the mindset shift.
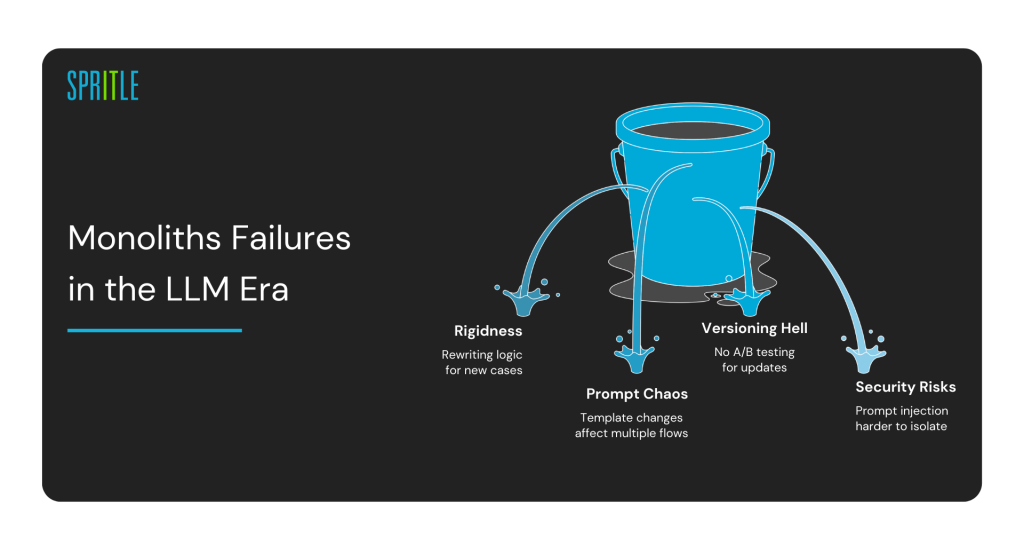
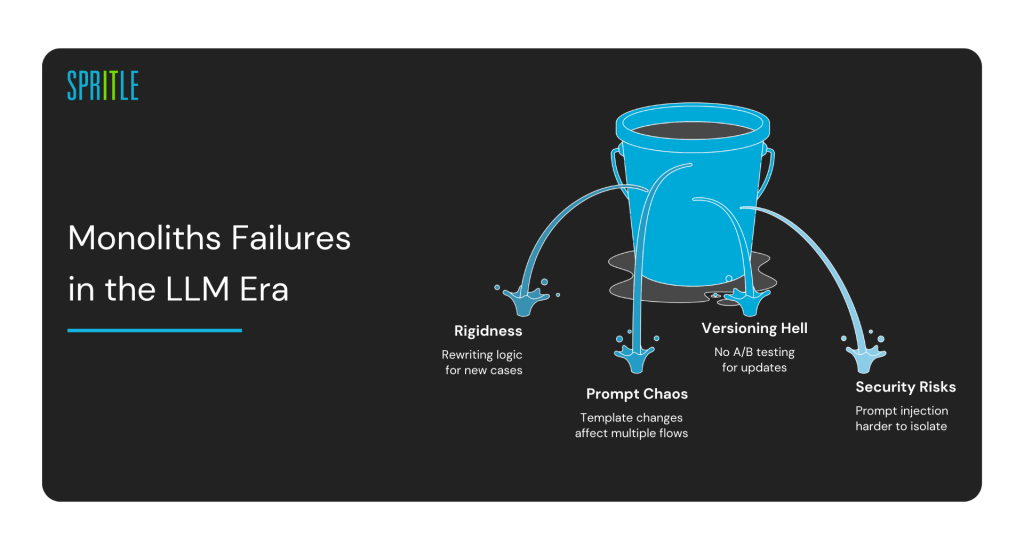
Why Monoliths Fail Fast in the LLM Era
Monolithic LLM products often start as internal experiments or hackathon wins. A few hard-coded prompts here, some clever chaining logic there. Before long, product logic, model calls, business rules, and UI bindings are all tangled together.
Problems emerge fast:
Rigidness: Adding new use cases often means rewriting existing logic.
Prompt Chaos: Changes in one prompt template affect multiple flows.
Versioning Hell: No clean way to A/B test prompt or model updates.
Security Risks: Prompt injection or data leaks become harder to isolate.
It’s like trying to add rides to a theme park where all the electricity runs through a single, ancient fuse box. One overload, and the whole thing goes dark.
What Plugin Architecture Looks Like in Practice
Let’s say your SaaS platform uses LLMs for five core features: summarization, sentiment analysis, chatbot, document Q&A, and compliance checks. With a plugin-based architecture:
- Each of these is a standalone module with its own prompt logic, retry strategy, rate limits, and fallback.
- A central orchestrator (custom or using tools like LangChain or LlamaIndex) dispatches user requests to the right plugin based on metadata or user intent.
- Each plugin can use different models (e.g., OpenAI for Q&A, Cohere for classification) and even hybrid approaches (LLM + rules).
- Testing and observability are scoped: you can monitor how each plugin performs independently.
- If one plugin fails or becomes costly, you can isolate and improve it without touching the others.
How This Accelerates Scaling
Rapid Experimentation: Want to test a new summarization strategy? Deploy a parallel plugin and compare outputs.
Domain Specialization: Tuning prompts or fine-tuning models becomes easier when scoped to a specific plugin.
Risk Containment: Bugs, hallucinations, or security issues stay isolated.
Flexible Upgrades: Swap out models, adjust logic, or implement caching — all without rewriting the app.
And perhaps most critically, plugin architectures foster team agility. Different squads can own different plugins, deploy independently, and move at their own speed. No more coordination overhead every time you want to iterate.
But It’s Not Just About Tech — It’s About Design Discipline
This all sounds great. But let’s be clear: plugin architectures don’t emerge automatically. They require:
- Clear abstraction boundaries
- Robust interface definitions (APIs, schemas, contracts)
- Careful prompt engineering within context constraints
- Consistent logging, observability, and monitoring
Frameworks like LangChain help, but they won’t enforce discipline. That’s where experienced partners like Spritle Software come in. We’ve seen what happens when teams go DIY or rely on off-the-shelf templates without architectural planning. You get quick demos, yes — but not sustainable systems.
We work with product teams not to “sell AI” but to architect for the long haul: helping you design modular systems, evaluate plugin boundaries, integrate safely with external APIs and data layers, and set up governance rails. Our mission isn’t to build once — it’s to help you keep building without breaking.
Metaphors Matter: Think Co-Pilots, Not Oracles
LLM plugins are like expert copilots. They don’t fly the whole plane, but they handle discrete, critical functions: reading weather, tuning the route, translating air traffic control instructions. You want each co-pilot well-trained, reliable, and scoped to their lane. Not a single know-it-all that might hallucinate the altitude.
And in a world where AI products are becoming mission-critical, that discipline isn’t optional. It’s strategic.
Looking Ahead: Composability Is the Future of AI
AI products will increasingly be systems of systems. Composable. Auditable. Extensible. The companies that succeed won’t be the ones who shipped the flashiest chatbot in 2024 — they’ll be the ones who can safely ship dozens of LLM-powered capabilities over time, each refined, accountable, and evolving.
That future isn’t built on magic. It’s built on architecture.
So before your next AI sprint, ask yourself:
Is our LLM logic modular?
Can we isolate, test, and swap parts?
Are we designing for scale, not just the demo?
And if the answer is “not yet” — we’d love to help.
Let’s make AI scalable, sustainable, and smartly designed. Together.
Need help architecting your LLM product for scale? Talk to Spritle Software’s AI team. We speak fluent prompt and practical engineering.