NVIDIA has unveiled the Nemotron Nano 2 family, introducing a line of hybrid Mamba-Transformer large language models (LLMs) that not only push state-of-the-art reasoning accuracy but also deliver up to 6× higher inference throughput than models of similar size. This release stands out with unprecedented transparency in data and methodology, as NVIDIA provides most of the training corpus and recipes alongside model checkpoints for the community. Critically, these models maintain massive 128K-token context capability on a single midrange GPU, significantly lowering barriers for long-context reasoning and real-world deployment.
Key Highlights
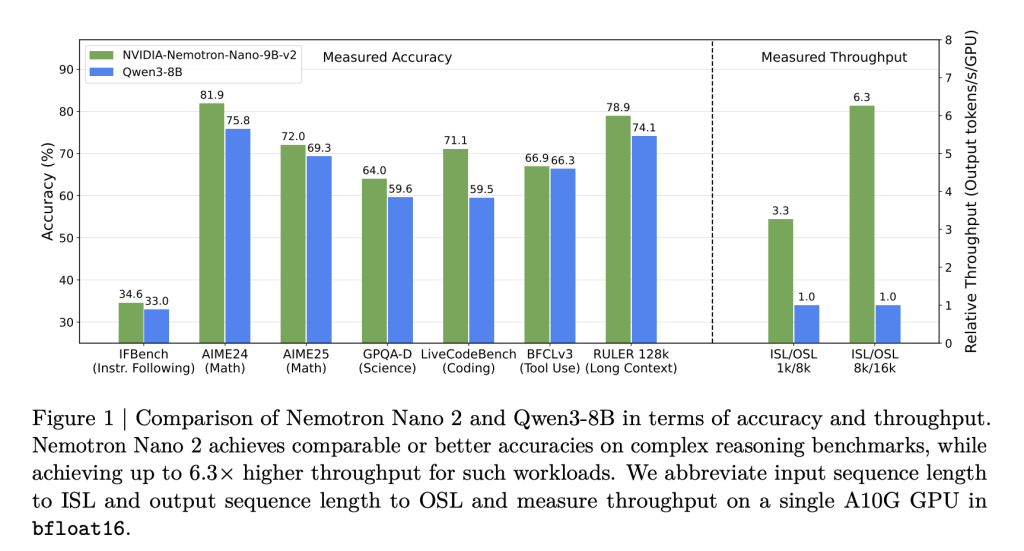
- 6× throughput vs. similarly sized models: Nemotron Nano 2 models deliver up to 6.3× the token generation speed of models like Qwen3-8B in reasoning-heavy scenarios—without sacrificing accuracy.
- Superior accuracy for reasoning, coding & multilingual tasks: Benchmarks show on-par or better results vs. competitive open models, notably exceeding peers in math, code, tool use, and long-context tasks.
- 128K context length on a single GPU: Efficient pruning and hybrid architecture make it possible to run 128,000 token inference on a single NVIDIA A10G GPU (22GiB).
- Open data & weights: Most of the pretraining and post-training datasets, including code, math, multilingual, synthetic SFT, and reasoning data, are released with permissive licensing on Hugging Face.
Hybrid Architecture: Mamba Meets Transformer
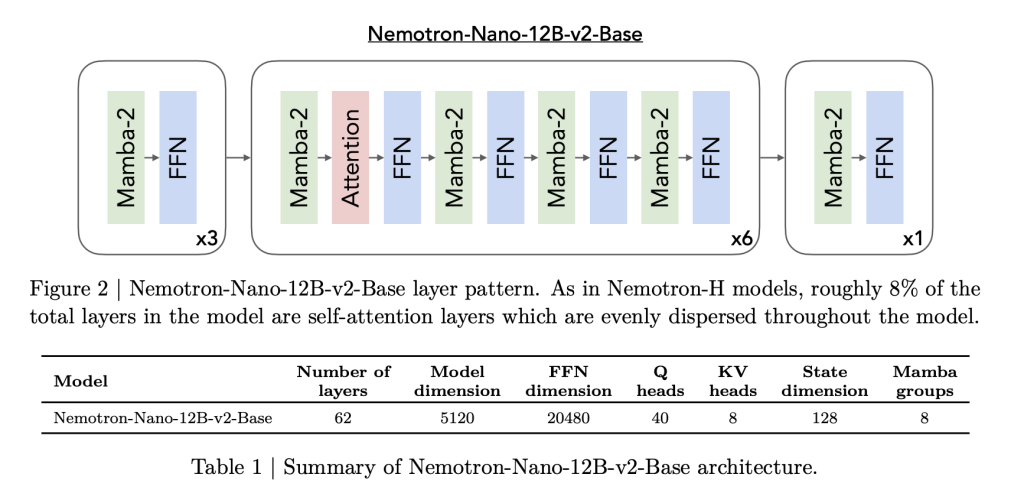
Nemotron Nano 2 is built on a hybrid Mamba-Transformer backbone, inspired by the Nemotron-H Architecture. Most traditional self-attention layers are replaced by efficient Mamba-2 layers, with only about 8% of the total layers using self-attention. This architecture is carefully crafted:
- Model Details: The 9B-parameter model features 56 layers (out of a pre-trained 62), a hidden size of 4480, with grouped-query attention and Mamba-2 state space layers facilitating both scalability and long sequence retention.
- Mamba-2 Innovations: These state-space layers, recently popularized as high-throughput sequence models, are interleaved with sparse self-attention (to preserve long-range dependencies), and large feed-forward networks.
This structure enables high throughput on reasoning tasks requiring “thinking traces”—long generations based on long, in-context input—where traditional transformer-based architectures often slow down or run out of memory.
Training Recipe: Massive Data Diversity, Open Sourcing
Nemotron Nano 2 models are trained and distilled from a 12B parameter teacher model using an extensive, high-quality corpus. NVIDIA’s unprecedented data transparency is a highlight:
- 20T tokens pretraining: Data sources include curated and synthetic corpora for web, math, code, multilingual, academic, and STEM domains.
- Major Datasets Released:
- Nemotron-CC-v2: Multilingual web crawl (15 languages), synthetic Q&A rephrasing, deduplication.
- Nemotron-CC-Math: 133B tokens of math content, standardized to LaTeX, over 52B “highest quality” subset.
- Nemotron-Pretraining-Code: Curated and quality-filtered GitHub source code; rigorous decontamination and deduplication.
- Nemotron-Pretraining-SFT: Synthetic, instruction-following datasets across STEM, reasoning, and general domains.
- Post-training Data: Includes over 80B tokens of supervised fine-tuning (SFT), RLHF, tool-calling, and multilingual datasets—most of which are open-sourced for direct reproducibility.
Alignment, Distillation, and Compression: Unlocking Cost-Effective, Long-Context Reasoning
NVIDIA’s model compression process is built on the “Minitron” and Mamba pruning frameworks:
- Knowledge distillation from the 12B teacher reduces the model to 9B parameters, with careful pruning of layers, FFN dimensions, and embedding width.
- Multi-stage SFT and RL: Includes tool-calling optimization (BFCL v3), instruction-following (IFEval), DPO and GRPO reinforcement, and “thinking budget” control (support for controllable reasoning-token budgets at inference).
- Memory-targeted NAS: Through architecture search, the pruned models are specifically engineered so that the model and key-value cache both fit—and remain performant—within the A10G GPU memory at a 128k context length.
The result: inference speeds of up to 6× faster than open competitors in scenarios with large input/output tokens, without compromised task accuracy.
Benchmarking: Superior Reasoning and Multilingual Capabilities
In head-to-head evaluations, Nemotron Nano 2 models excel:
| Task/Bench | Nemotron-Nano-9B-v2 | Qwen3-8B | Gemma3-12B |
|---|---|---|---|
| MMLU (General) | 74.5 | 76.4 | 73.6 |
| MMLU-Pro (5-shot) | 59.4 | 56.3 | 45.1 |
| GSM8K CoT (Math) | 91.4 | 84.0 | 74.5 |
| MATH | 80.5 | 55.4 | 42.4 |
| HumanEval+ | 58.5 | 57.6 | 36.7 |
| RULER-128K (Long Context) | 82.2 | – | 80.7 |
| Global-MMLU-Lite (Avg Multi) | 69.9 | 72.8 | 71.9 |
| MGSM Multilingual Math (Avg) | 84.8 | 64.5 | 57.1 |
- Throughput (tokens/s/GPU) at 8k input/16k output:
- Nemotron-Nano-9B-v2: up to 6.3× Qwen3-8B in reasoning traces.
- Maintains up to 128k-context with batch size=1—previously impractical on midrange GPUs.
Conclusion
NVIDIA’s Nemotron Nano 2 release is an important moment for open LLM research: it redefines what’s possible on a single cost-effective GPU—both in speed and context capacity—while raising the bar for data transparency and reproducibility. Its hybrid architecture, throughput supremacy, and high-quality open datasets are set to accelerate innovation across the AI ecosystem.
Check out the Technical Details, Paper and Models on Hugging Face. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.